我的 API 不可能這麼慢吧!看看 K6 怎麼拯救它

前言
透過刻意練習,我們能夠從實務中獲取經驗與不足,並且定期回顧自己用到什麼技術或工具。今天我們就回顧前幾天我們使用的測試工具 K6,本篇文章透過執行效能測試的步驟。
什麼是 K6
K6 是一款開放原始碼的負載測試工具,專為測試網站、API 及應用程序的效能而設計,類似的工具還有 Locust 、JMeter。K6 由 Grafana Labs 支持,能夠幫助開發人員和測試人員模擬高併發的使用者行為,測試系統在高負載下的表現,從而找出效能瓶頸並進行優化。
撰寫效能測試腳本的步驟
- 設計問題場景
想像我們有一個/api/users的 API,但由於資料庫查詢效率低,導致回應時間過長。這樣的問題會在高併發下更加顯著影響系統性能。 - K6 測試腳本模擬高併發負載
使用 K6 來模擬多個併發請求,測試 API 的回應時間和效能。 - 執行測試並分析報告
根據 K6 的報告,查看效能瓶頸的指標和統計數據。 - 找出問題並進行優化
根據報告的結果,找出問題並加以改善,例如加索引來提升資料庫查詢效率。
步驟 1:設計問題場景
假設我們有一個 API /api/users,這個 API 負責查詢用戶資料,但由於缺乏適當的索引,查詢速度很慢,特別是在高併發時,問題更加嚴重。
我們使用 SQLite 模擬一個無索引的場景,並撰寫簡單的查詢 API:
import express, {RequestHandler} from 'express';
import {Request, Response} from 'express';
import sqlite3 from 'sqlite3';
const app = express();
const port = 3001;
// SQLite 資料庫設置
const db = new sqlite3.Database('./test.db', (err) => {
if (err) {
return console.error('Error opening database', err.message);
}
console.log('Connected to SQLite database.');
});
db.serialize(() => {
db.run(`CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT,
email TEXT
)`);
// 新增大量資料來模擬效能瓶頸
db.run('BEGIN TRANSACTION');
const stmt = db.prepare('INSERT INTO users (name, email) VALUES (?, ?)');
for (let i = 0; i < 100000; i++) {
stmt.run(`User ${i}`, `user${i}@example.com`);
}
stmt.finalize();
db.run('COMMIT');
});
app.get('/api/users/:name', (req: Request, res: Response) => {
const sql = 'SELECT * FROM users WHERE name = ?'; // 查詢特定使用者
const userName = req.params.name;
db.all(sql, [userName], (err, rows) => {
if (err) {
res.status(500).send('Internal Server Error');
return;
}
res.json(rows);
});
});
app.use((err: Error, req: Request, res: Response, next: Function) => {
console.error(err.stack);
res.status(500).send('Something broke!');
});
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});
process.on('SIGINT', () => {
db.close((err) => {
if (err) {
console.error('Error closing database', err.message);
}
console.log('Closed SQLite database connection.');
process.exit(0);
});
});
步驟 2:K6 測試腳本模擬高併發負載
撰寫 K6 測試腳本來模擬高併發的查詢操作,測試查詢速度是否有性能瓶頸。
import http from 'k6/http';
import { sleep, check } from 'k6';
export const options = {
stages: [
{ duration: '1m', target: 100 }, // 在 1 分鐘內增加到 200 個併發請求
{ duration: '3m', target: 100 }, // 3 分鐘內保持 200 個併發請求
{ duration: '1m', target: 0 }, // 1 分鐘內降到 0 個請求
],
};
export default function () {
const userId = Math.floor(Math.random() * 1000000); // 隨機選擇一個使用者
const res = http.get(`http://localhost:3001/api/users/User ${userId}`); // 查詢指定使用者
check(res, {
'response time < 2s': (r) => r.timings.duration < 2000, // 檢查是否在 2 秒內完成
'status is 200': (r) => r.status === 200, // 檢查狀態碼是否為 200
});
sleep(1); // 每次請求後休息 1 秒
步驟 3:執行測試並分析報告
執行上述腳本後,K6 會生成詳細的效能報告,這些報告可以幫助我們找到系統瓶頸並進行優化。報告顯示查詢效率不佳,尤其是在高併發下,查詢速度明顯降低。
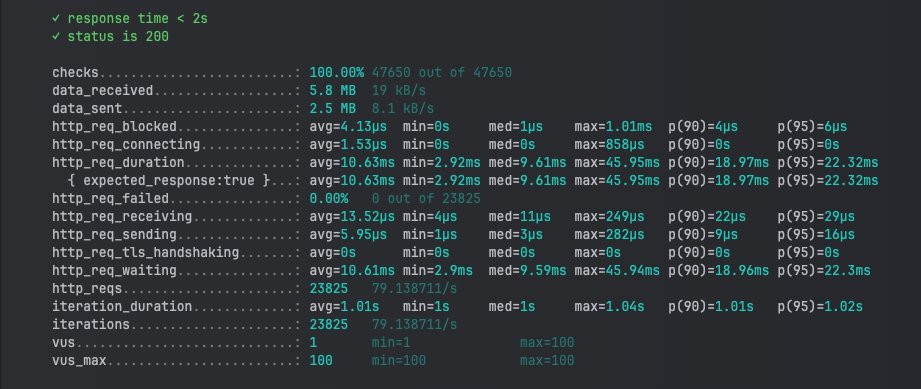
步驟 4:K6 報告中的效能問題
從上面測試結果可以看出明顯的性能瓶頸,可以發現 http_req_duration 平均的時間是 10.63ms,這也許就是未加索引導致查詢效率低的情況下導致的回應時間變長。
步驟 5:找出問題並且優化
透過 K6 的測試報告,我們可以推測 API 的問題可能出現在資料庫查詢效率低的部分,這導致 API 的回應時間過長。接下來,你可以考慮進行以下優化:
- 增加索引:目前最明顯的瓶頸是資料庫查詢速度過慢,應該針對查詢頻繁的列(如 id 或 name)添加索引,這將大幅提升查詢效率,縮短回應時間。
- 提升資料庫性能:除了增加索引外,還可以考慮對資料庫進行優化,如調整查詢快取、資料分區等。
步驟 6:優化後重跑測試
要進一步比較,接下來你可以為 name 欄位加上索引,再次執行查詢,並比較加上索引和未加索引的查詢時間差異。
db.serialize(() => {
db.run(`CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT,
email TEXT
)`);
// 新增索引
db.run('CREATE INDEX idx_users_name ON users(name)', (err) => {
if (err) {
return console.error('Error creating index', err.message);
}
console.log('Index created.');
});
db.run('BEGIN TRANSACTION');
const stmt = db.prepare('INSERT INTO users (name, email) VALUES (?, ?)');
for (let i = 0; i < 100000; i++) {
stmt.run(`User ${i}`, `user${i}@example.com`);
}
stmt.finalize();
db.run('COMMIT');
});
沒有增加索引的結果
新增修改完之後的 K6 報告
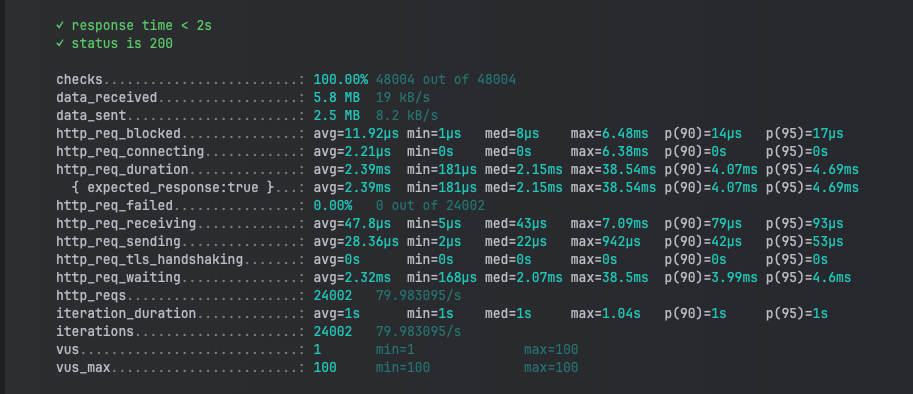
可以看到 http_req_duration 從原本的 10.63ms 變到 2.39 ms,加了索引後,系統的查詢效率明顯提升,回應時間顯著降低,等待時間減少,整體處理速度提升。對於高併發的情境來說,索引優化是提升效能的有效方法,特別是在涉及大量資料查詢的系統中。
延伸問題
- 當資料庫查詢是系統瓶頸時,除了加索引,還有其他可以優化的方法嗎?例如,快取、資料庫分頁?
- 當併發量增加時,索引的作用是否能夠持續顯著地改善查詢時間?在超高併發下,系統還會出現其他瓶頸嗎?考慮測試更高的併發數量,觀察效能是否仍然穩定,並探索如何進行進一步的效能調整
結論
效能測試是識別系統瓶頸的重要方法,而透過 K6 這樣的工具,可以方便地模擬高併發情境,並詳細記錄效能數據。通過這篇文章,我們成功模擬了一個 API 的效能問題,並展示了如何分析和優化程式碼,在進行測試的時候,我們會不斷的假設可能的問題,並且透過執行測試驗證併分析結果。