你的系統能撐過巨人的進擊嗎?迎戰週年慶流量浪潮

前言
最近雙 11 和百貨週年慶又快到了,光是想到那短時間內用戶如巨人般湧入網站,我才不會害怕!我害怕的是荷包變瘦!。但這時候,我們還是要考慮網站系統會瞬間承受巨大的流量衝擊,像是迎接一場巨大的戰鬥。今天,我們就來挑戰如何進行「尖峰期用戶行為模擬」的效能測試,讓你的系統在這樣的尖峰時段依然能夠穩定運行。
挑戰目標
在某些特定的時間點(如大型促銷活動或節假日),用戶行為會產生異常的峰值流量,例如短時間內大量商品加入購物車或支付請求同時發送。
挑戰設計下列測試場景:
- 場景 1:模擬用戶在尖峰時段同時進行購物車操作(如一次性加入數千商品),測試系統在處理大量請求時是否會出現性能問題。
- 場景 2:測試用戶在高峰時同時提交訂單,系統是否能夠正確處理並保持一定的回應速度。
- 場景 3:測試在極端高峰(如秒殺活動)下,系統是否能夠平穩運行,並在流量回落後迅速恢復。
衝擊測試(Spike Testing)
衝擊測試是模擬系統突然受到高流量衝擊時的表現,目的是檢查系統是否能夠快速響應突發情況,並在流量回落後迅速恢復穩定。
系統架構
graph LR;
A[Load Balancer] --> B[Web Servers]
B --> C[Application Servers]
C --> D[Database Cluster]

購物車的 Restful API
購物車(Shopping Cart)API 的回應時間會因系統的規模、架構、使用的技術堆疊等因素而有所不同,但通常來說,以下是一些合理的範圍:
- 理想狀況:API 回應時間應該保持在 100ms 至 500ms 之間,這能提供非常流暢的用戶體驗。
- 可接受的範圍:對於一般購物車操作,回應時間在 500ms 至 1秒 之內也是可以接受的,尤其是在伺服器處理或網路延遲 (Latency) 較大的情況下。
- 尖峰情況:在尖峰流量或大量併發的請求下,回應時間如果不超過 2秒,通常仍然能夠被視為合理。不過,回應時間超過 2秒 就會開始影響用戶體驗,特別是當進行商品新增、更新數量或結帳等操作時,這些操作對即時性要求較高。
| HTTP 方法 | API 路徑 | 描述 |
|---|---|---|
| GET | /cart | 查看購物車內容 |
| POST | /cart | 新增商品到購物車 |
| PUT | /cart/{productId} | 更新購物車中指定商品的數量 |
| DELETE | /cart/{productId} | 移除購物車中的指定商品 |
| DELETE | /cart | 清空購物車 |
| POST | /cart/checkout | 對購物車進行結帳並創建訂單 |
測試場景 1:模擬用戶在尖峰時段同時進行購物車操作。
步驟:
- 模擬 5000 名同時使用者,在短時間內提交「加入購物車」請求,每個請求包含多達數千件商品。
- 測試請求是否能夠在 2 秒內完成。
- 驗證是否有失敗請求或錯誤回應,並檢查系統資源(如 CPU、記憶體)的消耗。
預期結果:
- 系統能在大量併發處理所有的「加入購物車」請求,無錯誤或超時。
- 資源消耗保持在合理範圍內,不會導致系統崩潰或明顯的性能下降。
在實踐效能測試的時候,必須要考慮實際業務的場景,以場景 1 為例,網站可能原本只有 100 多個使用者同時在線,而這些使用者並不全部都在購物車,有的可能是在瀏覽商品、有的可能在搜尋商品,也有可能不斷地更新、移除購物車的行為,像這些也是同時要考慮在內。
衝擊測試(Spike Testing):主要模擬的是系統在短時間內突然遭遇非常高的流量衝擊。它關注的是系統能否在極短時間內應對流量急速增加的情況,並在流量回落後能否迅速恢復穩定。這種測試的重點在於模擬流量的急劇增減,特別是瞬間的負載高峰。
場景 2 和場景 3 的測試策略與場景 1 類似,以下將只針對場景 1 進行測試與分析。
K6 測試腳本
這個腳本簡單來說是用來模擬高併發的使用者行為,快速測試網站在負載高峰下的反應。它會在 2 分鐘內將虛擬使用者數量快速提升到 5000,然後在 1 分鐘內快速降回 0,模擬一個瞬間高流量的場景。
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
stages: [
{ duration: '2m', target: 5000 }, // fast ramp-up to a high point
{ duration: '1m', target: 0 }, // quick ramp-down to 0 users
],
};
export default () => {
const urlRes = http.post('http://localhost:3333/api/cart');
const resultCheck = check(res, {
'response time < 2s': (r) => r && r.timings && r.timings.duration < 2000,
'status is 200': (r) => r && r.status === 200, // 檢查回應狀態
'no failed requests': (r) => r && r.status !== 0, // 檢查是否有失敗請求
});
if (!resultCheck) {
console.error('Some checks failed');
}
sleep(1);
};
每個虛擬使用者 (UV) 會向購物車 URL (/api/cart) 發送 POST 請求,並進行以下檢查:
- 請求是否在 2 秒內完成(檢查 response time)
- 回應狀態碼是否為 200(表示請求成功)
- 是否有失敗的請求。
如果有任何檢查失敗,會顯示錯誤訊息。最後,每次請求之間會有 1 秒的延遲 (sleep(1)) 來模擬真實的使用者行為。
使用 K6 執行這個測試腳本
K6_WEB_DASHBOARD=true k6 run stress.js
- VUs:Virtual Users,模擬同時使用者的數量。
- http_reqs:HTTP 請求的數量,模擬大量請求的發送。
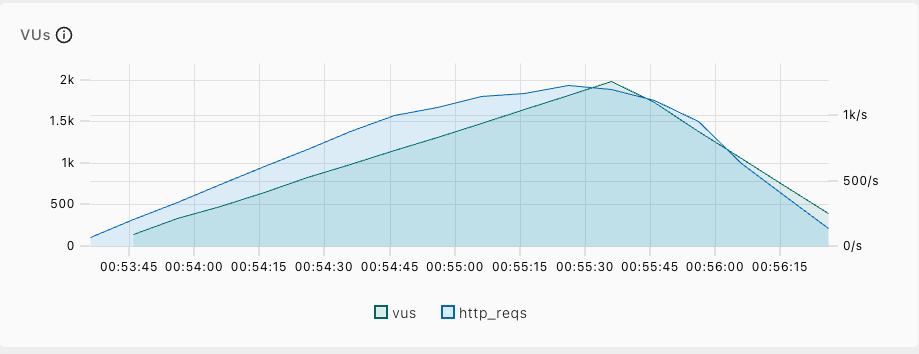
通常 HTTP Request Failed 會是 0/s,但如果開始出現錯誤的情況就會使用 The USE Method 和 The TSA Method去查看資源問題。
辨識效能瓶頸與優化
辨識效能瓶頸的目的是找出系統中導致性能問題的關鍵資源或過程,例如 CPU 過載、記憶體不足、網路延遲等。一旦找到瓶頸,下一步就是進行優化,調整相關配置或代碼來提升系統效能。這是一個持續的過程,通常需要多次測試和調整來確保系統達到最佳狀態。
以這個測試場景為例,我通常會有下列幾種方法去分析是否有效能上的瓶頸:
- 相關性分析:例如當 CPU 負載過高時,可能會導致 API 的回應速度增加,透過這類型的分析我們可以找出系統裡面的某個問題或是特定資源。例如:在最新版的作業系統中發現原本會使用 GPU 進行計算,因為 kernal 的某個 bug/設定,導致只能使用 CPU 計算,進而讓 CPU 負載過高,API 回應的時間也變長。
- 證據查找:如果發現 API 因為 衝擊測試(Spike Testing)的關係導致某些時間 API 回應非 200 的狀態碼 (status code),我們就要透過日誌 (Log) 或是監控的資料、錯誤訊息去找尋 API 失敗的原因,有可能是連線問題、或是處理的訊息佇列容量(Message Queue)已經滿了,等等原因。
接著我們可以透過分析業務流程的處理時間,找到花費最久的地方,甚至有些監控資料能夠列出某段時間處理最久的資料庫查找 (SQL)、或是透過查看程式碼或檢查每個關鍵函式處理的時間,進而透過程式碼分析,找到可能的效能瓶頸。
練習
- 試著完成場景 2、場景 3 的效能測試,是否需要採取和場景 1 的測試情境呢?
結論
面對流量如巨人般的湧入,我們的系統需要經得住這場「巨人進擊」。設計多種測試場景,像是尖峰負載模擬,能讓我們在流量高峰時提前發現潛在的效能瓶頸。透過衝擊測試、效能分析以及優化策略,我們可以讓系統在壓力之下依然表現得遊刃有餘。這不僅僅是一個技術挑戰,更像是一場對抗巨人的戰鬥,確保你的系統能在巨人的進擊中站穩腳跟。不過,即使我們能找到並解決系統上效能瓶頸,恐怕也無法突破我荷包上的天花板瓶頸啊!